Just as popular search terms can reflect the news, sports and entertainment events going on in a particular country at any point in time, looking as search engine queries to predict future behaviour is not new either.
Search engine Google itself has published research through the journal Nature and on its Google.org site showing that there is a close correlation between how many people are searching for flu-related keywords, and how many people have actually developed the symptoms of flu. Whilst not everyone who looks-up keywords relating to flu is going to have it themselves, it is likely that they’ll know someone who has developed it, or there is an outbreak in their local area. So Google, looking at the popularity of searches and where they are clustered, can determine where flu is most prevalent in near-real time.
But Google’s Flu Trends analysis is all about modelling events that have happened in the past. Can search terms be used to predict likely future behaviours?
The UK’s Bank of England seems to think so. In 2011 they concluded that using search terms they could out-perform the most traditional data points used to predict the country’s economic performance. Using Google’s Insights for Search they found that not searches for “estate agents” would increase ahead of spikes in house prices. And now new research suggests that searches for particular stock market and finance related keywords may help to predict stock market movements.
Using data public data from Google’s Trend service, researchers analysed the search volume of 98 different keywords between 2004 and 2011 – and compared these keywords against movements in the US Dow Jones Industrial Average (DJIA).
The research showed, perhaps counter intuitively, that the volume of searches for keywords such as “stocks and “revenue” went down ahead of rises in the DJIA, and conversely searches for finance keywords went up ahead of a fall in the DJIA.
The researchers put this search behaviour down to the concept of loss aversion. Where people are concerned about the stock market and the value of their investments they tend to gather more information about the stock market and their investment. The research team suggested that using their strategy of buying the DJIA as search volumes fell, and then selling as volume rose would have delivered a profit of 326%between 2004 and 2011 versus simply buying at the start of the period and selling in 2011.
It’s certainly an intriguing research paper, but does it stack up? Research elsewhere has shown that particular investments, such as Gold, go up with the amount of column inches in newspaper. And this seems more logical – if John Doe keeps reading in newspapers that Gold is a good investment and that the price is going up, he’s more likely to buy. And this in turn helps keep the price of gold up, which leads to further newspaper articles and more price rises. Why should the volume of search terms be any different?
Perhaps instead rather than looking at a broad spectrum of financial keywords and the rise and fall in volume, we should consider looking at particular investments – whether Gold, Oil or a particular stock or share. And further, that we try and look at the connotations or “emotion” of keywords associated with this. This will almost certainly give us a great insight into particular investments. An increase in keywords for “bullish”, “positive”, “above expectations” “record growth” and so on tied to a share or investment would surely be a sign that its price is only going to rise? And in the same way keywords for “profit warning”, “sluggish”, “bearish” and so on would seem to indicate an ever growing concern about the financial health of a particular investment.
And let’s take this a step further – having insights into how people perceive the products of a company can surely predict the future of the share price? Lots of negative sentiment about a product will lead to lower sales, perhaps a lot of products being returned, and ultimately a fall in profits. The share price will in turn head downwards.
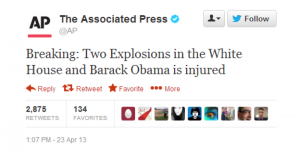
With “Big Data” the ability to not only collect all this information, whether from Google Trends, Twitter, new stories or wherever, makes this new kind of modelling a reality. We saw last week, with the hacking of Associated Press Twitter account that traders do already look to Twitter and social media for real time information to give them that extra edge.
Associated Press False Story Planted by Hackers Drives Share Prices Lower
But how long before we take out that human weakness to only be able to assimilate a few rather than millions of data points instantaneously? Remove that gut feel that many traders say drives their trades. With many firms already using algorithmic or “algo” “black box trading” to do high-frequency trading it’s not a big leap to see them using search terms and social media “big-data” to determine which investments to buy or sell.
7min read A website may be standing and still be in trouble. It may answer a request, return a cheerful 200 OK, and yet load slowly enough that visitors begin to lose patience. Its certificate may be nearing expiry. Its domain records may have changed. A server may be filling its disk in the background, patient and
6min read StatusCake tells you that something might be broken. Hermes can check whether it really looks broken, decide who should hear about it, send the email, and keep the record for tomorrow morning’s summary.
3min read The allure of OpenClaw is undeniable. You deploy a highly autonomous, self-hosted AI agent, give it access to your repositories and inboxes, and watch it reason through complex workflows while you sleep. It is the dream of the ultimate 10x developer tool realized. But as any veteran DevOps engineer will tell you: running an LLM-backed
7min read There are cloud outages, and then there are us-east-1 outages. That distinction matters because failures in AWS’s Northern Virginia region rarely feel like ordinary regional incidents. They tend instead to expose something larger and more uncomfortable: too much of the modern internet still behaves as though one place is an acceptable concentration point for infrastructure,
7min read Artificial intelligence is making software easier to produce. That much is already obvious. Code that once took hours to scaffold can now be drafted in minutes. Boilerplate, integration logic, tests, refactors and small internal tools can be generated with startling speed. In some cases, even substantial pieces of implementation can be assembled quickly enough to
10min read Whilst AI has compressed the visible stages of software delivery; requirements, validation, review and release discipline have not disappeared. They have been pushed into automation, runtime and governance. The real risk is not that the lifecycle is dead, but that organisations start acting as if accountability died with it. There is a now-familiar story about
James Barnes
April 2, 2026
Sign up for the StatusCake newsletter
Want to know how much website downtime costs, and the impact it can have on your business?
Find out everything you need to know in our new uptime monitoring whitepaper 2021