




Want to know how much website downtime costs, and the impact it can have on your business?
Find out everything you need to know in our new uptime monitoring whitepaper 2021

There is a common saying in the software development field:
“Repetition is the root of all software evil.”
The more you repeat yourself in code, the more likely you are to make mistakes or cause yourself issues down the line when you come to update things. The aim is to keep things DRY!
It’s a common interview question and the reason your PR might be getting rejected. The DRY principle stands for “Don’t Repeat Yourself” and was first introduced to the masses by Andy Hunt and Dave Thomas in the book The Pragmatic Programmer, their definition of the DRY principle is as follows:
“Every piece of knowledge must have a single, unambiguous, authoritative representation within a system. The alternative is to have the same thing expressed in two or more places. If you change one, you have to remember to change the others”
So, pretty straight-forward, right? The aim is to avoid duplication to save yourself time when you first write the code as well as yourself, or other people’s time in the future when changes need to be made. Something particularly clever the authors of the book made clear was that DRY isn’t specifically against repeated code, rather repeated knowledge.
So, what exactly is a piece of knowledge in this context?
My interpretation of the word knowledge is that it is meant to refer to one of the following:
Let’s look at an example of what I mean for each of these three things.
Say we have a couple of methods as seen below, we have two functions that return a specific set of properties from an object and return them as a formatted string. The system front-end likes this specific form of sting output, so you need to make sure your methods all provide a consistent output.

But what happens if your front-end changes and there is a need to alter the way we format the output to accommodate this change? We’d have to go and update each method (there may be more than just two!). Wouldn’t it be better if we had a single source of truth for the way we output our strings?

Here you can see that I’ve moved the string formatting logic out of the two original methods into a helper method. Now if we need to make a change, we can do it at this one location with no need to update all the other methods. No more duplicated code or knowledge.
This one is pretty simple, but you can often find yourself writing code containing string or numeric literals where capturing that value in a variable with a meaningful name would be preferable, take this code for example:
Here we have a function that takes the wholesale price of a product and adds some form of sales tax. It’s perfectly functional code and makes sense to the person whole wrote it, but what if we were using that 20 value to mean the same thing elsewhere in the code. Well first off, we would be violating the DRY principle of never repeating ourselves and secondly, we would be making a headache for ourselves or others in the future if needed to update this value if the sales tax changed.
Moving the value into a descriptive variable not only means you only need to update the value in one place, but it also adds meaning to the context it’s being used in.
I struggle with this one quite a lot, I tend to be a bit of a serial code commenter! Check out this code I wrote for a side project of mine:

Are all those comments required to understand the code? No! not at all, as I’ve done a pretty good job of naming the variables contained in the method, the code is self-describing. The extra comments were just a waste of my time and just extra words for a reviewer of the code to read. And like any project where code is updated and comments are not, the link between the two will potentially drift and just become confusing.
These are just a few examples of where you can apply the DRY principle to not only simplify your code but to cut down on potential errors and unnecessary code edits in the future.

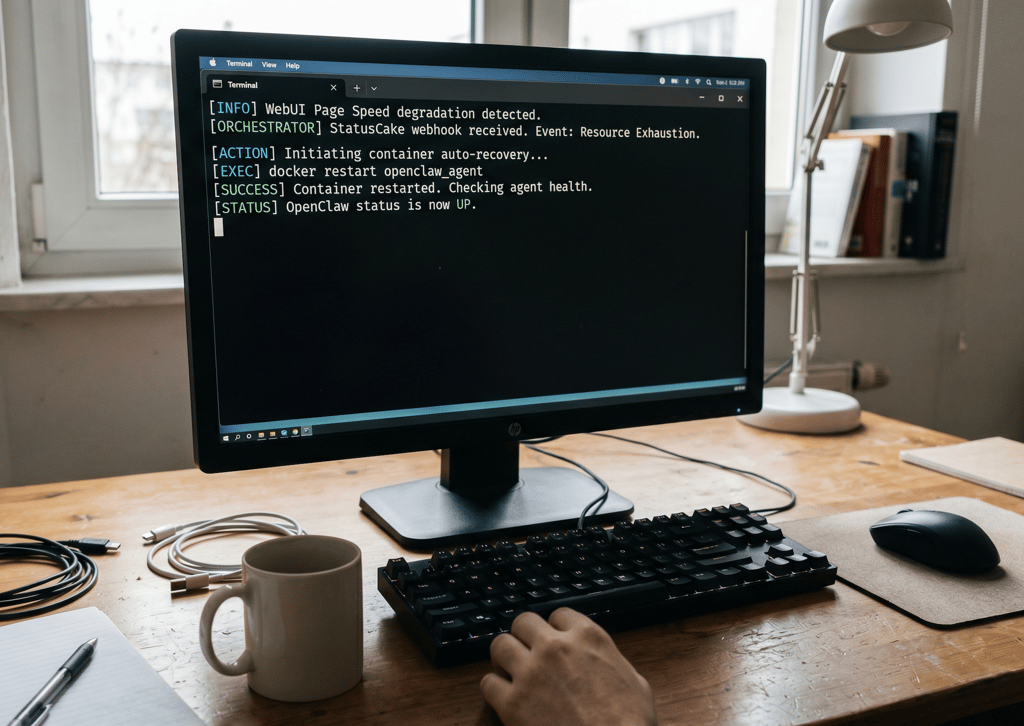
3 min read The allure of OpenClaw is undeniable. You deploy a highly autonomous, self-hosted AI agent, give it access to your repositories and inboxes, and watch it reason through complex workflows while you sleep. It is the dream of the ultimate 10x developer tool realized. But as any veteran DevOps engineer will tell you: running an LLM-backed
7 min read There are cloud outages, and then there are us-east-1 outages. That distinction matters because failures in AWS’s Northern Virginia region rarely feel like ordinary regional incidents. They tend instead to expose something larger and more uncomfortable: too much of the modern internet still behaves as though one place is an acceptable concentration point for infrastructure,
7 min read Artificial intelligence is making software easier to produce. That much is already obvious. Code that once took hours to scaffold can now be drafted in minutes. Boilerplate, integration logic, tests, refactors and small internal tools can be generated with startling speed. In some cases, even substantial pieces of implementation can be assembled quickly enough to
10 min read Whilst AI has compressed the visible stages of software delivery; requirements, validation, review and release discipline have not disappeared. They have been pushed into automation, runtime and governance. The real risk is not that the lifecycle is dead, but that organisations start acting as if accountability died with it. There is a now-familiar story about
4 min read How AI Is Shifting Software Engineering’s Primary Constraint For most of the history of software engineering, the primary constraint was production. Code was expensive, skilled engineers were scarce, and shipping features required concentrated human effort. Velocity was limited by how fast people could reason, implement, test, and deploy. That constraint shaped everything from team size,
5 min read Autonomous Code, Trust Boundaries, and Why Governance Now Matters More Than Ever In Part 1, we looked at how AI has reduced the cost of building monitoring tools. Then in Part 2, we explored the operational and economic burden of owning them. Now we need to talk about something deeper. Because the real shift isn’t