Want to know how much website downtime costs, and the impact it can have on your business?
Find out everything you need to know in our new uptime monitoring whitepaper 2021
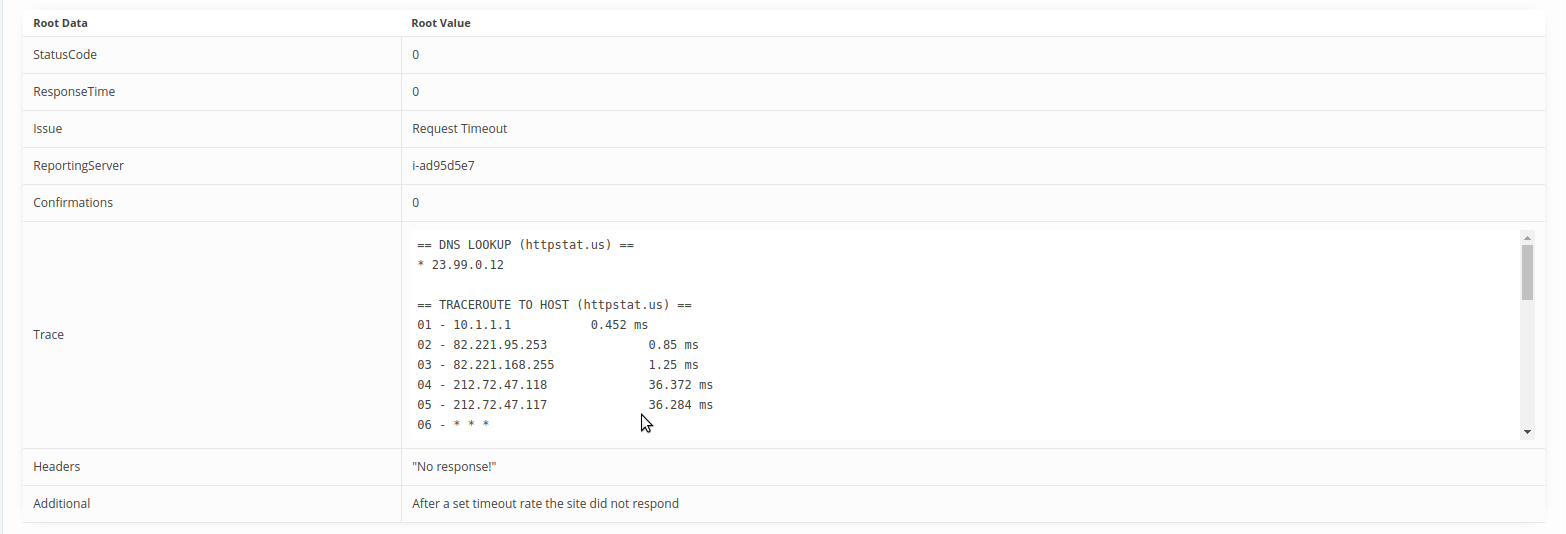
We’ve today made it a lot easier for you to identify of timeout related downtimes with the addition of two new functionalities to our “Root Downtime Causes” section.
Now you can see both a Traceroute and a DNS check details in the event of a timeout on any HTTP type test within your account, if you are looking for the Enhanced root downtime causes then these can be found below the “Status Periods” section, in the portion of the page marked “Root Downtime Causes”
In order to view the new info in the event of a timeout on one of your tests, simply click the “Details” button next to a Root Cause entry. You’ll then see a full summary of the DNS test and Traceroute. These new stats are only available on our paid plans, so you’ll need a subscription to take advantage of the heightened detail!