
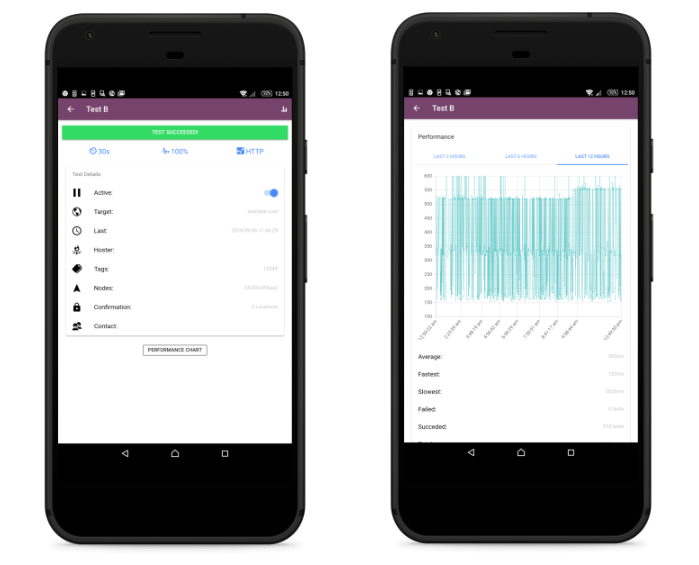
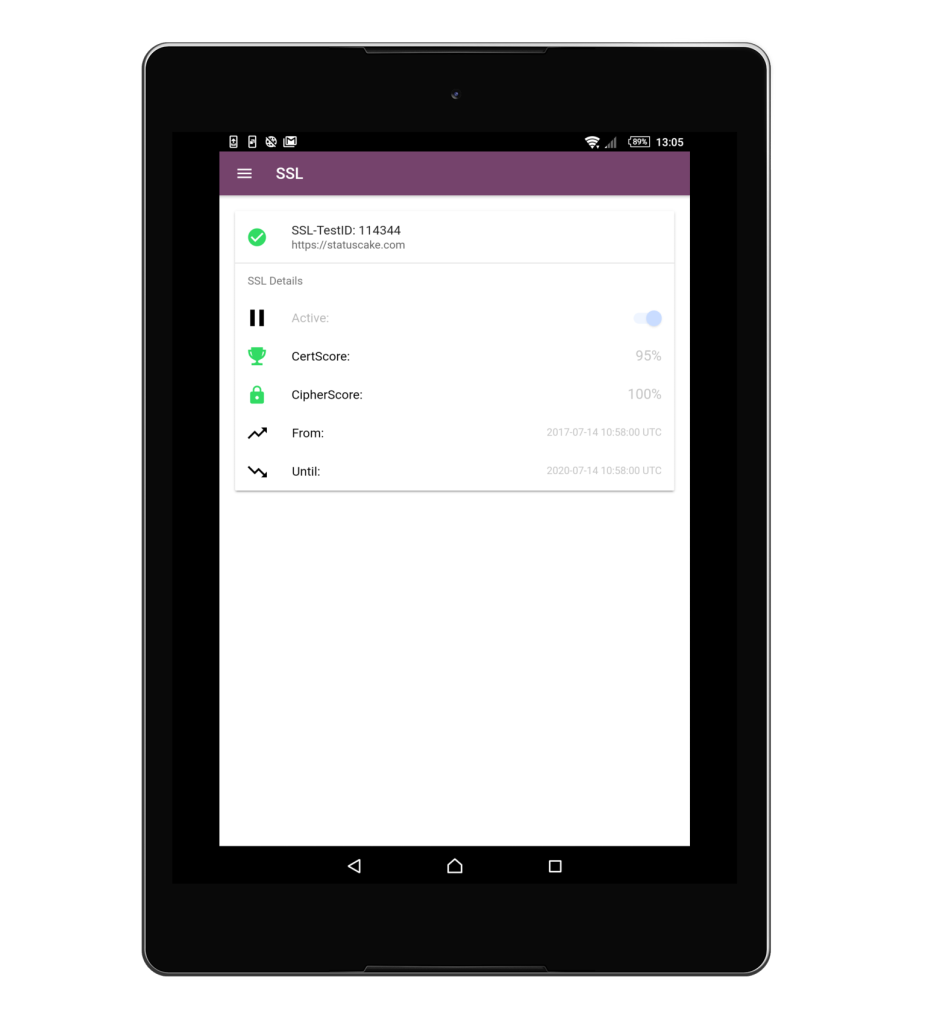
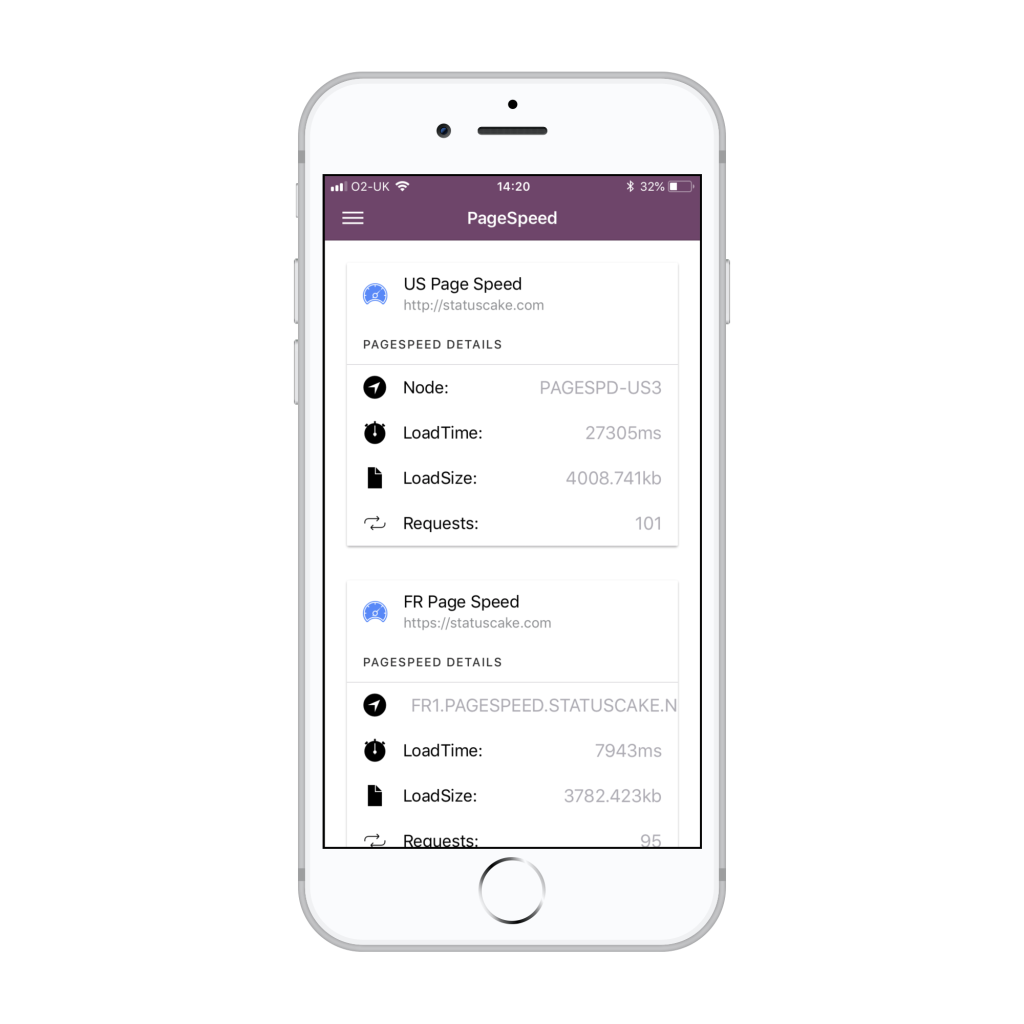
 In order to log in to the StatusCake app for Android and iOS you will need to obtain your username and API key from within the StatusCake account. Both of these details can be obtained within the
In order to log in to the StatusCake app for Android and iOS you will need to obtain your username and API key from within the StatusCake account. Both of these details can be obtained within the
Website Monitoring Checklist: What to Track Beyond Uptime
7 min read A website may be standing and still be in trouble. It may answer a request, return a cheerful 200 OK, and yet load slowly enough that visitors begin to lose patience. Its certificate may be nearing expiry. Its domain records may have changed. A server may be filling its disk in the background, patient and
