The allure of OpenClaw is undeniable. You deploy a highly autonomous, self-hosted AI agent, give it access to your repositories and inboxes, and watch it reason through complex workflows while you sleep. It is the dream of the ultimate 10x developer tool realized.
But as any veteran DevOps engineer will tell you: running an LLM-backed Node.js agent in production is vastly different from testing it on your local machine.
When traditional web applications break, they usually have the courtesy to throw a hard 500 error or crash entirely. Autonomous agents, however, are notorious for failing silently. They burn through token limits, get trapped in infinite hallucination loops, cannibalize server RAM during heavy context window crunches, or simply abandon cron jobs without logging a single fatal error.
At StatusCake, we’ve watched the community transition from experimenting with OpenClaw to relying on it for mission-critical infrastructure. To make that leap safely, “deploy and forget” is not an option. You need a production-grade observability stack, and more importantly, you need automated triage.
Here is how you build it.
Why AI Agents Require a New Approach to Monitoring
Monitoring an OpenClaw instance requires you to track both the infrastructure health (is the Node process alive?) and the cognitive health (is the agent actually executing tasks?).
If you are only pinging the unauthenticated /health endpoint, you are flying blind. You might know the server is powered on, but you have no idea if the internal SQLite memory database is corrupted or if the agent is deadlocked on an external API rate limit.
To gain true visibility into OpenClaw’s operations, you need a multi-layered approach.
The Production-Grade Observability Stack
We recommend deploying five specific check types to cover the entire surface area of an OpenClaw deployment:
- 1. Gateway Verification (HTTP): Don’t settle for basic uptime. Point a StatusCake HTTP check at the
/api/status endpoint, passing your gateway.auth.token via a Bearer header. This validates that internal routing is functional and the memory database is actively readable.
- 2. Tunnel Integrity (Domain/SSL): OpenClaw requires broad system permissions. If you are exposing port
18789 via a reverse proxy to receive external webhooks, an expired SSL certificate or hijacked DNS record is a critical vulnerability.
- 3. External Integration Health (SMTP): If your agent manages email workflows, it cannot intuitively diagnose provider outages. Independent SMTP monitoring isolates bottlenecks instantly, proving whether a failure is due to a broken prompt or a downed mail server.
- 4. Execution Accountability (Heartbeat): To catch silent failures and task deadlocks, append a simple
curl payload to your scheduled SKILL.md scripts. If StatusCake doesn’t receive the expected push ping, you know the agent dropped the ball.
- 5. Resource Management (Page Speed): LLMs are resource-hungry neighbors. By monitoring the load time of your OpenClaw Web UI, you create an early-warning system. If load times jump from 800ms to 4000ms, your Node.js backend is suffocating under a heavy reasoning loop, giving you time to right-size your VPS before it crashes.
Deep Dive: Want the exact configuration settings and technical rationale for this setup? Read our comprehensive Knowledge Base guide: Configuring StatusCake Monitoring for OpenClaw Deployments.
Closing the Loop: Building a Self-Healing Agent
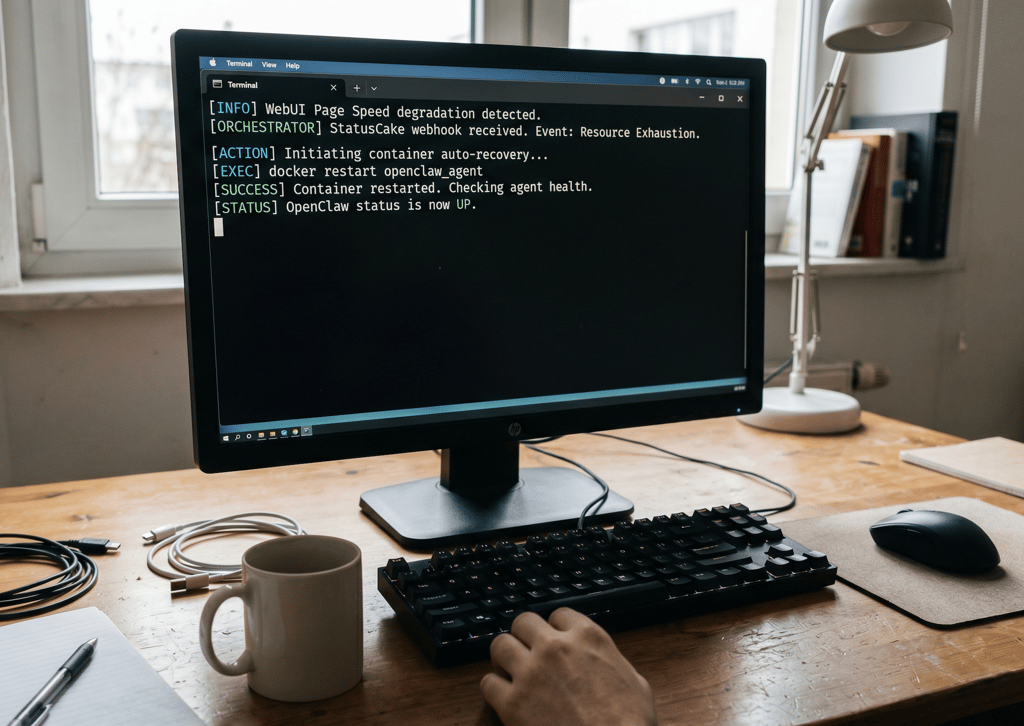
Monitoring is only half the battle. If your OpenClaw instance exhausts its server resources at 3:00 AM, an email alert isn’t a solution—it’s an interruption. True autonomy means the system should attempt to heal itself before paging a human operator.
By leveraging StatusCake Webhooks, you can bridge the gap between knowing there is a problem and executing the solution.
Because OpenClaw cannot catch its own lifeline if its gateway has crashed, the architectural secret is to deploy an independent “Orchestrator” (like a lightweight Express server or n8n instance) alongside your agent.
When StatusCake detects degradation, it fires a POST payload to your orchestrator, which then maps the specific alert to a local CLI triage command. For example:
- Resource Exhaustion (Page Speed Alert): The listener triggers
docker restart openclaw to clear memory bloat.
- Corrupted Internal State (HTTP Alert): The listener triggers
openclaw doctor --fix to repair broken session locks and restore routing.
- Silent Task Deadlocks (Heartbeat Alert): The listener dumps the last 100 lines of the agent’s logs for you to review later, then forcefully restarts the queue.
Deep Dive: Ready to build your own auto-recovery orchestrator? We’ve provided the architecture mapping and a complete Node.js listener script in our advanced guide: How to Build a Self-Healing OpenClaw Agent using StatusCake Webhooks.
Autonomy Requires Supervision
Deploying an AI agent is a massive step forward in workflow automation. But letting a machine execute shell commands, manage databases, and communicate on your behalf without guardrails is a liability.
By layering StatusCake’s global monitoring network over your OpenClaw instance and wiring those alerts into a self-healing webhook architecture, you transform a fragile AI experiment into a resilient, production-ready system.
Set up your checks, configure your orchestrator, and finally let your agent do what it was built to do: operate reliably in the shadows.